
Introduction
A few months ago, I decided to take a stab at building a Farcaster AI agent, whose purpose would be to help users navigate Farcaster by answering their questions and pointing them to relevant content. The idea was to train it on hundreds of hours of video content from GM Farcaster, the live show NounishProf and I host to cover everything happening in the Farcaster ecosystem. People have called our video archive a time capsule of Farcaster history. The problem is video isn’t inherently searchable like text, so there was no way for people to interact with all that content.
I had been wanting to train an LLM on our content, but I hadn't done anything about it. Partly because I didn't know where to start or what was involved, partly because I'm not a developer and thought it would be hard, partly because we were focused on other priorities. But seeing the explosion of AI agents like Aether, mferGPT, AskGina.eth, Atlas, and Clanker pop up on Farcaster made me want my own special purpose bot even more. Seeing Six’s comment about Aether was the final catalyst that got me to take action. He casted:
It's true that anybody can make a bot/ai agent for any community - the tech is all out there in the open.
But anybody can do a lot of things, so much so that the statement becomes meaningless. Out of the set of people who can do something, only a few people /actually/ do it, and within that set, even fewer people actually do it in a way that is valuable.”
And I decided then I had to stop waiting and just do it.
For context, I’ve worked in tech for over 20 years, starting out as a software engineer, but it's been a long time since I wrote any real code myself. With the help of a developer friend I met through Farcaster and AI as a coding copilot, I started working my way through the steps toward an MVP.
In this post, I’ll share the journey of building GMFC101, a Farcaster AI agent that has access to all the video content from the GM Farcaster Network. I’ll cover the concept and vision for the bot, the architecture and tools I used, and the features I’ve built so far. I’ll also share the challenges I faced along the way and what’s next on the roadmap.
This post is for people who have ever wondered what it takes to build an AI bot, or who just want to hear about the highs and lows of experimenting with AI.
The Purpose of GMFC101
The original vision for GMFC101 was simple: build an AI bot to help new users onboard to Farcaster. I wanted it to act as a friendly assistant, trained on our Farcaster 101 video series, guiding users through the basics of the platform and introducing them to Farcaster’s unique culture. At first, that was the MVP—a small, focused bot that could answer questions about onboarding and point users to specific Farcaster 101 videos.
But as the project evolved, so did the bot’s purpose. With access to hundreds of hours of video content from the GM Farcaster Network (Farcaster 101, GM Farcaster episodes, Vibe Check, The Hub, and Here for the Art) the bot is now a resource for all Farcaster users, whether they’re brand new or have been around since the early days.
What does GMFC101 do?
When users tag the bot and ask a question, it searches our entire archive of transcripts and responds using relevant information pulled from our content. If it finds an answer in one of our videos, it recommends the video and provides a direct link, timestamped to the exact moment the topic is discussed.
Who is it for?
GMFC101 is for anyone on Farcaster, but it can be particularly useful for new users trying to understand the platform. Farcaster has a lot of unique language, culture, and history that can be overwhelming at first. The bot makes it easier to dive in by offering answers, context, and recommendations for content they might not have otherwise found.
What problems does it solve?
Makes video content searchable – Video is not an inherently searchable medium. With hundreds of hours of content across our network, finding episodes where we talked about certain topics used to be impossible. GMFC101 makes it easy to search for specific topics and surface key moments from Farcaster’s history and lore.
Makes content interactive – Instead of passively watching videos, users can engage with GMFC101, turning content into a conversation, all without leaving their social feed.
Provides a Farcaster Knowledge Base – Farcaster is constantly changing as it evolves. The core team behind Farcaster is focused on finding product-market fit, not on documenting the journey to get there. That’s where GM Farcaster comes in. The bot helps make our content more accessible, especially for those who miss our live shows.
The Solution: RAG (Retrieval-Augmented Generation)
How does one go about building a bot with specific expertise? In my case, I wanted to give my bot deep knowledge of GM Farcaster video content. There are different ways to approach this, but two of the most popular options are LLM fine-tuning and RAG (Retrieval-Augmented Generation).
I chose the RAG approach for GMFC101.
Here’s how it works: Instead of fine-tuning the LLM on all your data (which can be time-consuming and expensive), you keep your knowledgebase in an external database. When a user asks the bot a question, you retrieve relevant information from your database and inject it into the prompt for the LLM to use in its response.
For example, if a user asks, “What does wowow mean?” which is a very Farcaster specific question, the base LLM model won't have that information or be able to answer it. But since we've covered that topic in our Farcaster videos, we can use RAG to help the LLM give a good answer. Using RAG, the prompt to the LLM would look something like this:
“Answer the question: ‘what does wowow mean?’ using the following information: ‘wowow is a meme that emerged from low effort replies and became popular, if you type wowow in your cast, the like button turns into a wowow reaction... ,’” (where that information was pulled directly from our transcripts).
This approach allows the bot to respond with accurate, context-specific answers without needing to be fully retrained. The key is having a reliable method for extracting, storing, and retrieving relevant knowledge—which I'll cover in the next section.
A note on Eliza:
Eliza is a popular open-source framework for building conversational AI agents. While powerful, it wasn’t the right fit for my project. It felt like overkill for what I wanted to do, and I was more interested in learning and being hands-on rather than relying on a library.
Architecture & Component Overview
I built two main systems, each their own code repository:
The Transcript Pipeline: A process for turning YouTube videos into text transcripts in a format that the bot can interact with (aka embeddings, more on this below).
The Bot: An API endpoint that gets triggered when someone mentions the bot and handles the workflow of generating and posting a response.
These two systems work together: the pipeline prepares the transcript data, while the bot uses that data to answer user questions. The entire system is built in a modular, component-based way, making it easy to modify or improve individual parts as needed. The three main components are:
Transcript Management – This is everything involved in making high quality transcripts for the bot to interact with. High-quality data is critical because the bot’s unique knowledge comes directly from these transcripts. The old database mantra "garbage in, garbage out" is still true in the age of LLMs.
RAG & Semantic Search – This component turns transcript text into vector representations (embeddings) for semantic search. It’s how the bot retrieves relevant knowledge to include in its responses. By keeping this process modular, I can easily swap out components in the future, like changing the vector database or embedding model, without affecting the rest of the system.
Prompt & Response Generation – This is the part that decides what information to give the AI to get the best possible answer. It builds a customized prompt for each user question by including things like relevant transcript snippets, previous parts of the conversation, and controls to make sure the bot doesn’t respond with too much or too little detail. This component is what turns raw data into a helpful, human-like reply.
Of course, there are also supporting components for tasks like logging, archiving, and monitoring. These are important, but the three core components above have the biggest impact on the bot’s ability to get the job done.
1. The Pipeline: Making Transcripts Available to the Bot
The pipeline is an automated process that takes a YouTube video and turns it into a format the bot can interact with. In my case, the end result is storing the transcript in two different formats - one as embeddings and one as full text - that the bot has access to. The pipeline is built to run in either batch mode (processing multiple videos) or single-video mode (for ongoing updates or redos).
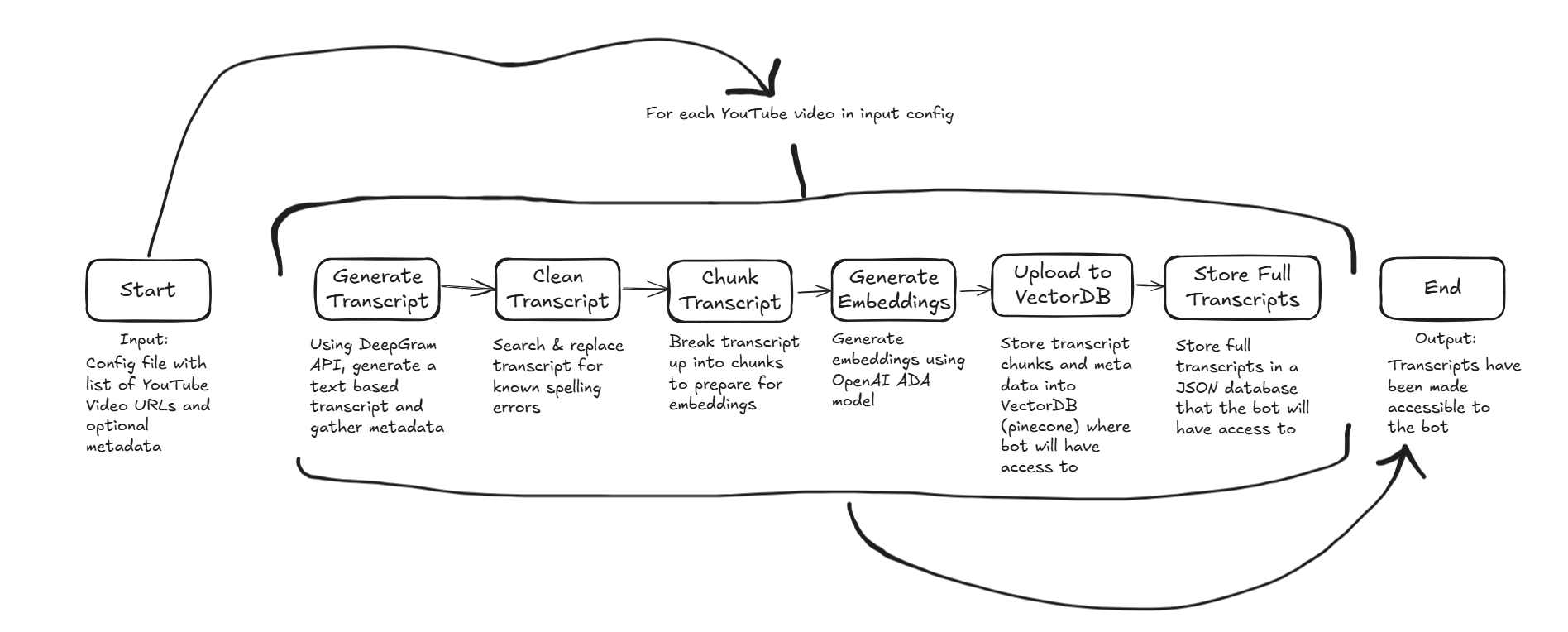
Pipeline Steps for each video
Generate Transcript – I used Deepgram to create a high-quality transcript from the YouTube video. Starting with a YouTube URL, the API turns it into a JSON file with the full transcript as one field, with sections that also break the transcript up into sentences, paragraphs, words, and it even has information about speakers. It doesn't have names for the speakers yet (just speaker1, speaker2, etc.) but that's something that can be added later.
Clean the Transcript – Corrects common spelling errors (like dGen → degen and NannishPrav → NounishProf). As good as Deepgram is, it's still hard to get high quality transcripts when we use so many names and words in the Farcaster ecosystem that are not common. I originally built this step to update the values directly in the VectorDB without re-calculating the embedding but later took the time to move it earlier in the pipeline so I could safely rerun files when I discover spelling errors. This is an important step because embedding values will change depending on spelling.
Chunk the Transcript – It's either impossible or not advisable to generate embeddings on large chunks of data. So, this step takes the transcript file and splits it into smaller sections for embedding. I went with 500 characters based on the embedding model I was using.
Generate Embeddings – Using OpenAI’s
text-embedding-ada-002model, each chunk is converted into a vector representation.Upload to a Vector DB - Embeddings are stored in a Vector DB for fast semantic search. I went with Pinecone. I started by using upsert so I could rerun a file, and then later changed it to delete/re-insert so I could safely rerun files that I wanted to manually clean or fix the transcript for.
Store Full Transcript and Metadata – The full transcript and metadata (e.g., episode title, date, YouTube URL) are stored in a JSON database that the bot has access to. I have one single JSON file that contains the metadata for every episode that has been processed, and a single JSON file for each episode containing the full transcript.
Quick note on embeddings if you are not familiar with its meaning or why it's necessary:
Think of an embedding is a numerical representation of a piece of text. Imagine taking a sentence and turning it into a unique string of numbers that captures its meaning and context. These numbers live in something called vector space, which allows the bot to compare and search through them based on their similarity.
When a user asks the bot a question, the bot converts that question into an embedding and compares it to the embeddings from all the transcript chunks. The most similar ones are returned as context for the answer.
Embeddings is the technical term for how "semantic search" works.
2. The Bot: From Webhook to Response
While the pipeline prepares transcripts so the bot can interact with them, the actual bot itself is an API. When someone tags @gmfc101 on Farcaster, Neynar handles the webhook and calls the API which handles the bot's response.

Bot Flow:
Event Triggered – The Neynar webhook detects when the bot is tagged or mentioned.
API Call – The webhook calls my API hosted on Render.
Semantic Search – The API queries my vector DB (Pinecone) to find the most relevant transcript chunks based on the user’s question.
Prompt Preparation - A custom prompt is prepared that includes relevant transcript chunks and video metadata as context. For example, if the question is "What is a frame?", the prompt might look something like this:
"You are an expert in Farcaster culture. Use the provided context from GM Farcaster Episode 123 which aired MM/DD/YYYY, to answer the user's question. The user's question is: 'What is a frame?' Context: 'A frame is...[information from our transcripts]'"
Generate Response – Using OpenAI’s LLM, the bot crafts a response based on the transcript content and episode metadata. The prompt itself plays a huge role in how good the response is. However, because AI responses are non-deterministic (the same inputs produce different outputs, results are not reproducible), getting consistent, high-quality results is tricky.
Reply on Farcaster – The bot posts a reply with the answer and a link to the relevant video, including a timestamp if applicable.
Tools & Tech Stack
To build GMFC101, I used a combination of tools across several categories: dev tools and coding assistants, APIs, and infra & hosting. I am using the free or lowest usage/priced tier for all of them. Here’s a summary:
Dev Tools & Coding Assistants
Cursor Pro– A lightweight IDE built on vscode, with Claude 3.5 Sonnet integrated as its AI copilot that made writing code faster and easier. $20/month.
ChatGPT – My overall project copilot. While Cursor was writing most of the code, I used ChatGPT as my mentor/guide at a high level for the entire project. $20/month (Probably don't need both Cursor AI and ChatGPT but it's a sunk cost as I was already paying for this.)
GitHub – Used for version control of the project’s codebase and for supporting automated deployments. $0/month
Postman – Used for local API testing and debugging webhook responses. $0/month
APIs
Deepgram – Used to generate transcripts from YouTube videos, recommended by an experienced dev as being one of the services with the best accuracy. It came with $200 in free credits and I haven't needed to pay for anything additional yet. $0/month
OpenAI APIs – I used APIs for two purposes: 1.) creating and searching embeddings using the
text-embedding-ada-002model, and 2.) for getting LLM responses to user queries by sending in prompt usinggpt-4model. Paying for usage as I go, my monthly bills during this early development stage with only light usage for the bot are in the $10 - $20 /month range.Neynar – The first (and biggest? only?) player in the Farcaster Infrastructure space. While Farcaster data is 100% open and accessible for anyone to integrate with, neyar makes it easy with APIs and tooling. I am using several Neynar tools including 1.) the webhook that detects when @gmfc101 is tagged on Farcaster and triggers the bot to respond, 2.) an API that summarizes a thread conversation for additional prompt context, and 3.) an API which sends the bot's reply as a new cast. I'm on the lowest tier, starter plan, at $9/month
Infra & Hosting
Pinecone – A vector database that stores transcript embeddings for semantic search across all content. I am on the free tier and with such light usage during this early development stage, I'm not even coming close to the limits of the free tier across storage, read and write units. $0/month
Render – Hosts the production API, and is set up with CD for automated deployments anytime I check in new code. I'm on the free tier called hobby plan, $0/month
Current Features & Capabilities
Here’s what the bot can do right now:
Answer User Questions – Any Farcaster user can tag @gmfc101 and ask it a question about Farcaster. The bot responds with relevant information pulled from our video transcripts.
Video Recommendations with Timestamps – If the answer is found in a specific video, the bot recommends that video and provides a direct link to the exact moment the topic is discussed.
Contextual Memory – The bot can engage in multi-turn conversations, remembering the context of previous questions within the same conversation.
Massive Knowledge Base/ Access to Full GM Farcaster Network Content – Initially, GMFC101 was trained only on Farcaster 101 videos. It now has access to all 200+ GM Farcaster episodes, as well as Vibe Check, The Hub, and Here for the Art.
Lessons Learned Throughout the Process
I built an MVP in just 5 days of work, with the help of a mentor, AI copilots, and modern tooling. I continued to iterate over the course of the next several months, using AI as my guide. The process has been fun and rewarding with several key learnings along the way:
1. Thin Vertical Slice Development
The project scope could have been overwhelming because going into this I knew nothing about how to develop on Farcaster, how to integrate LLMs into code, or how to get video transcripts. Instead of getting bogged down in too many details, I focused on building a small, functional MVP that worked end-to-end. I knew once I had something working, it would be much easier to identify what needed improvement and iterate from there. This approach helped me avoid rabbit holes and kept the project moving forward.
2. Code Quality Still Matters in the Age of AI
Even with AI copilots, code quality is still crucial. I prioritized modularity and simplicity, which made it much easier to swap out components later. For example, if I decide Pinecone isn’t the right vector database, or if I want to use Claude instead of ChatGPT for handling replies, I can swap them out without rewriting the entire system. Keeping code clean and maintainable from the start is a gift to future me.
3. You Can’t Avoid the Schlep
Transcription errors have been a constant source frustration. The bot would call NounishProf “NanishPrav” and “degen” became “dGen.” These mistakes came directly from errors in the transcripts. Garbage in, garbage out. Someday I'll need to spend hours upon hours cleaning up every transcript (schlep). Fow now, I choose not to spend too much time on this because I'm choosing progress over perfection. But I know if I want exceptional results, I'll eventually have to revisit this step. As of now, I dont know any shortcuts.
4. Prompt Engineering is Real
The difference between a good prompt and a great one is enormous. It took several iterations to improve how the bot handled context, recommended videos, and to get it to stick to Farcaster’s 1024-character limit. Getting the bot to provide YouTube links in plain text (not markdown) was another unexpected challenge. The process of refining the prompt never really ends, but it's easy to iterate as I go.
5. Stay Niche
I got distracted comparing GMFC101 to bots like Aether and AskGina.eth and all the other bot accounts that are just really good. They feel more human, have memory and natural conversations, and can take all sorts of actions on Farcaster and onchain. I started trying to add comparable functionality to GMFC101, but quickly realized it was a waste of time, as I remembered the purpose of my bot.
GMFC101’s value is in its unique access to GM Farcaster video transcripts. No other bot can surface Farcaster lore from hundreds of hours of video content. I decided to lean into that niche and stay focused on making GMFC101 the best at what it does: answering questions about Farcaster’s culture and history.
Let’s See It in Action
If you want to see it in action yourself, just tag @GMFC101 on Farcaster and ask it a question. Or, check out some of these examples of the bot replying to real users asking it questions.
▼Who were the cypherpunks?
▼Can you tell me about the special episode we held last year with chicbangs.eth focused on mental health?
▼What does it mean to lock degen??

▼Can you tell me anything about basecamp?

▼What's the deal with "tipping"?
Challenges & Problem Areas
Here are some of the challenges I faced while building GMFC101:
Transcript Quality. Transcript quality is a constant challenge. Spelling errors, filler words like ums and ahs, and speakers talking over each other all degrade accuracy. Transcripts also miss key video context—like screen sharing, facial expressions, and visual references—which can make parts of the conversation confusing or incomplete. Since the bot relies entirely on transcripts, poor-quality input leads to poor-quality responses. It’s a problem I’ll need to tackle eventually to take GMFC101 to the next level.
Infinite Loop with Another Bot. Shortly after its initial release, GMFC101 got into an infinite conversation loop with another bot because both were programmed to respond anytime they are tagged. It was comical, but pointless, and would rack up my AI bill if left unchecked.
Solution: Hardcoded a stop once the conversation reaches a certain depth and added a prompt warning to the user when it’s one step away from that limitSearch Accuracy & Context Limits. Early searches pulled transcripts that were relevant for the user's query, but the chunks were too small, so the bot's answers were often too vague or incomplete.
Solution: Kept the chunk size the same for creating embeddings and for searching for content, but then expanded the context window around each chunk—adding 10 sentences before and after—to give the bot more to work with.Metadata Queries. The bot struggles with metadata-driven questions like “Who were the guests on episode 100?” or “How many times has DWR been on the show?” These require a different approach than semantic search.
Solution: Working on a routing system that detects question types and chooses the right search path—metadata or transcript.Longitudinal Questions & Trend Summaries. The bot handles specific questions well but struggles with trend-based queries like “What were the most iconic cultural moments on Farcaster in 2024?”
Solution: Experimenting with techniques to summarize content and trends over time.Prompt Design. Prompt design is a constant iteration process and warrants its own dedicated blog post. I've gone through many iterations to get the bot to answer questions appropriately, recommend videos accurately, and maintain multi-turn conversations. Some challenges were surprisingly difficult: getting the bot to respect character limits under 1,000 characters, ensuring it provided YouTube links as plain text instead of markdown, and figuring out how to give it the right personality (something I’m still working on).
Solution: Continual iteration on the prompt, adding explicit instructions for handling text format, limiting response length, and improving conversational flow.Limited Testability. Testing was another challenge. Since there’s no dedicated test environment for Warpcast, I had to test everything in production, including sending replies. While simulating an environment is technically feasible, simulating a back and forth conversation between a bot and a user was more effort than expected, especially because I wasn’t as familiar with Farcaster’s data objects.
Roadmap & What's Next
GMFC101 is still very much a work in progress, and there’s a lot more I want to build. Here’s what’s on the roadmap:
Train the Bot on More Content – Continue expanding its knowledge base with additional shows and interviews.
Introduce Question Routing – Right now, the bot uses semantic search for everything, but metadata-driven questions (like “Who were the guests on episode 100?”) need a different approach. I’m working on a routing system that will detect the question type and choose the right search path—metadata or transcript. (See this anthropic blog post which describes workflow routing as a pattern)
Add More Farcaster-Specific Features – I’d love for GMFC101 to have more farcaster native capabilities and be able to do some stuff onchain. The bot account has both an ETH and SOL connected wallet, but it doesn't do anything with them yet. I can start teaching the bot how to tag people and channels, recommend accounts to follow, and highlight popular communities on Farcaster, like casts, and other capabilities to become more "human" like a regular farcaster user
Memory & Conversation Tracking – The bot can handle short conversations now, but I'd love if it had more conversational ability to feel more human, and had memory across multiple conversations and the ability to surface relevant past discussions.
Differentiate Speakers – Right now, the bot doesn’t distinguish between me and NounishProf in transcripts. Teaching it to recognize speakers will improve the accuracy of its responses.
Make it Smarter - This is an evergreen effort with multiple aspects. Sometimes the bot answers perfectly; other times, it hallucinates. The goal is to improve reliability and consistency in its responses. There’s no single fix—this work will require improvements across several areas, including enhancing transcript quality, improving semantic search, refining its personality, and continuous prompt iteration.
Final Reflections
Building GMFC101 has been fun and rewarding. It reminded me how much joy there is in problem-solving and coding, even after years of being away from hands-on development. AI copilots are a game-changer, making it possible to go from zero to a working MVP in about 5 days. But as powerful as they are, having a solid foundation in coding and architecture patterns was crucial to making the right decisions and catching mistakes.
There’s still a lot more I want to build, but this experience reinforced something I've long believed in: the best way to learn something new is to dive in, start small, and iterate.
If you’ve ever thought about building your own AI bot, my advice is just to do it. You’ll be surprised by how much you can learn, and how much fun you’ll have, along the way.

